Predictive Modeling of Political Contributions
Project Overview
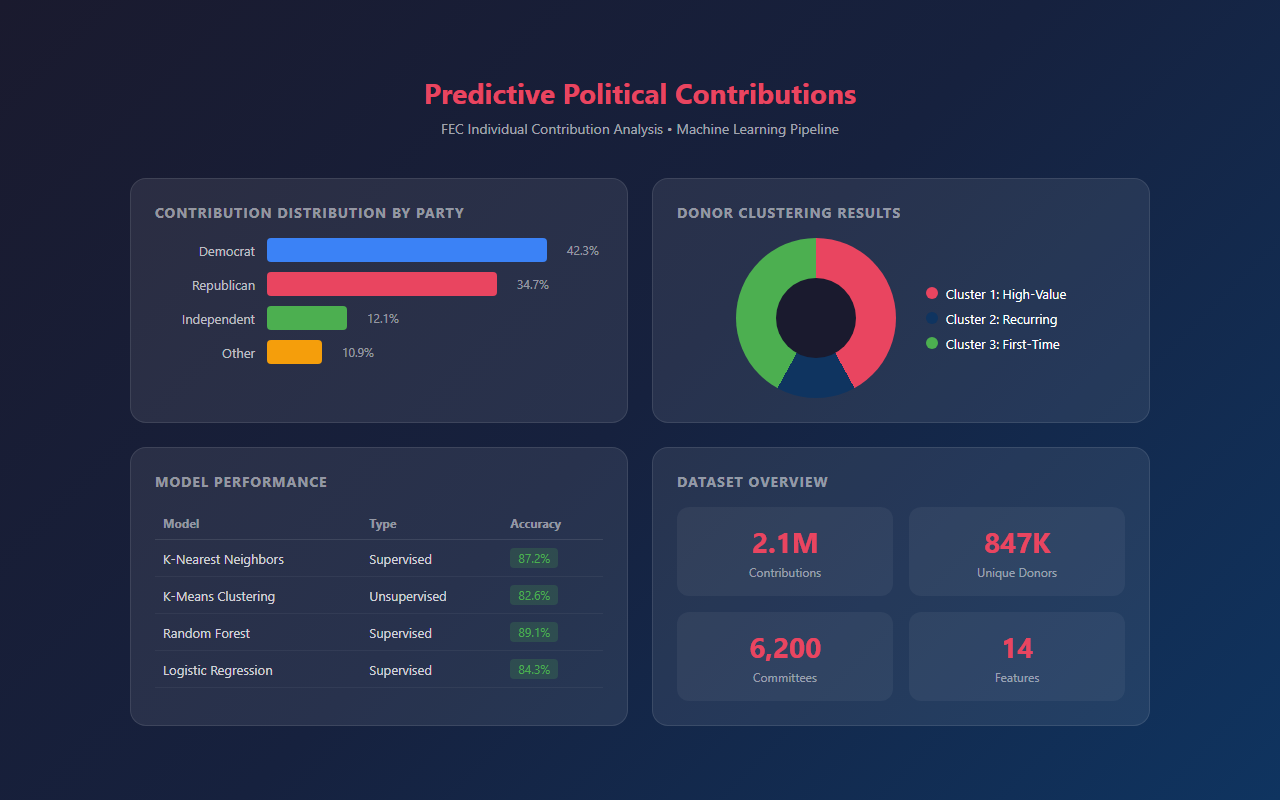
This project analyzes Federal Election Commission (FEC) individual contribution records to build predictive models of political donations. Using real-world campaign finance data, the goal was to explore patterns in political giving and develop models that can predict donation behavior, party affiliation based on contribution patterns, and donor clustering.
The FEC dataset includes detailed records of individual contributions to political campaigns, committees, and organizations across the United States. This rich dataset provides an ideal foundation for applying machine learning techniques to understand political behavior.
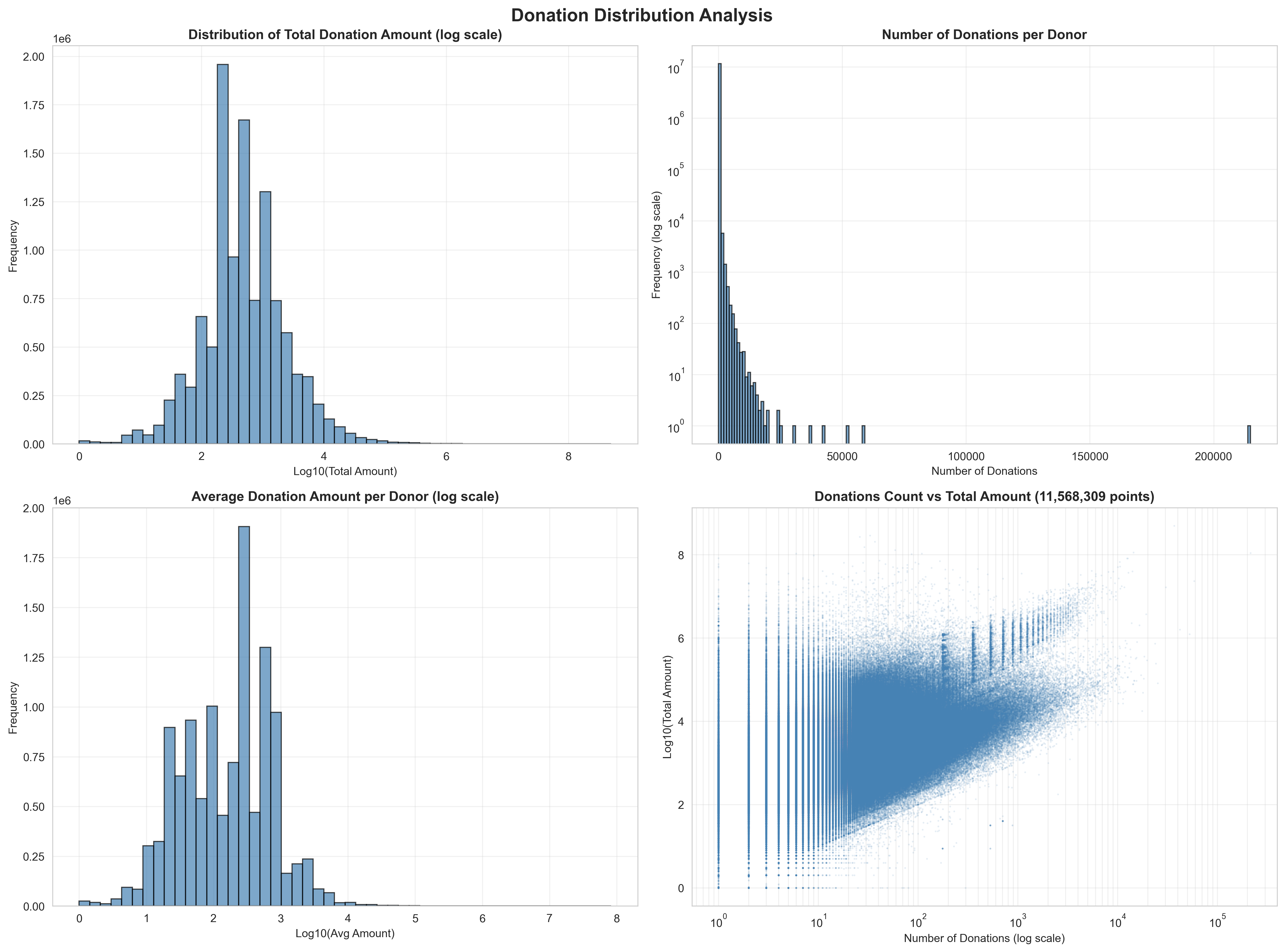
Donation distribution analysis across 11.5 million contribution records
Key Features
- Campaign Data Pipeline: Automated import and normalization of FEC candidate, committee, and linkage data
- Contribution Parsing: Raw contribution record processing with configurable parallel workers for handling large datasets efficiently
- Exploratory Data Analysis: Comprehensive EDA with visualizations to uncover patterns in donation amounts, timing, geographic distribution, and donor demographics
- Supervised Learning Models: Party prediction and donation likelihood classifiers trained on contribution features
- Clustering Analysis: K-Means clustering with KNN indexing to identify natural groupings among donors
- Model Comparison Framework: Systematic evaluation and comparison of different model approaches
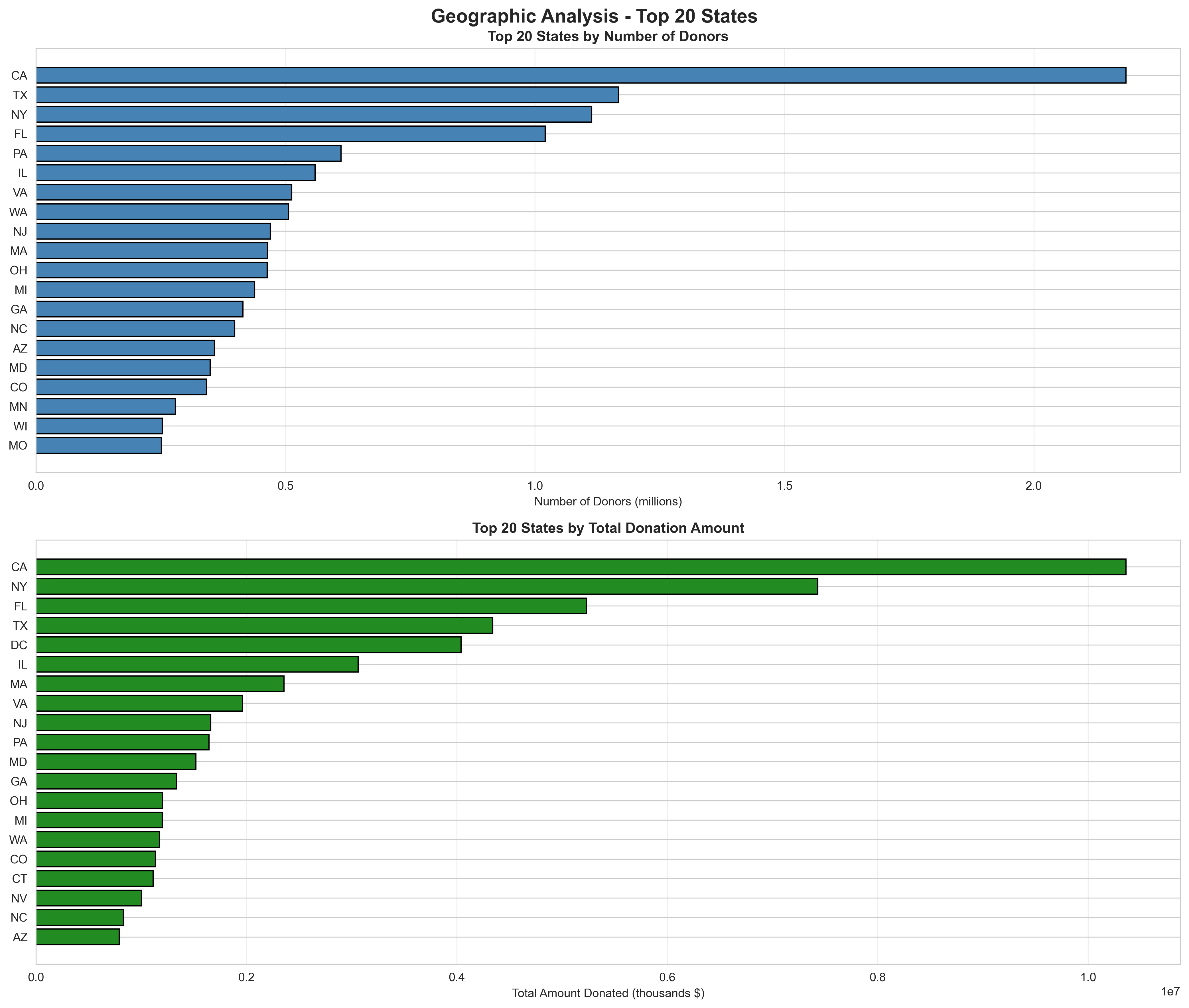
Geographic analysis of donors and donation amounts by state
Technical Architecture
The project follows a structured data science pipeline built entirely in Python:
- Data Ingestion: Scripts to download and import FEC bulk data files into a local database, with environment-based configuration for credentials
- Feature Engineering: Transformation of raw contribution records into meaningful features for model training, including temporal, geographic, and financial features
- Model Training: Separate modules for supervised learning (classification) and unsupervised learning (clustering), organized under a models directory
- Parallel Processing: Configurable worker pools for handling the large volume of FEC records efficiently
- Reporting: Automated generation of analysis reports and visualizations
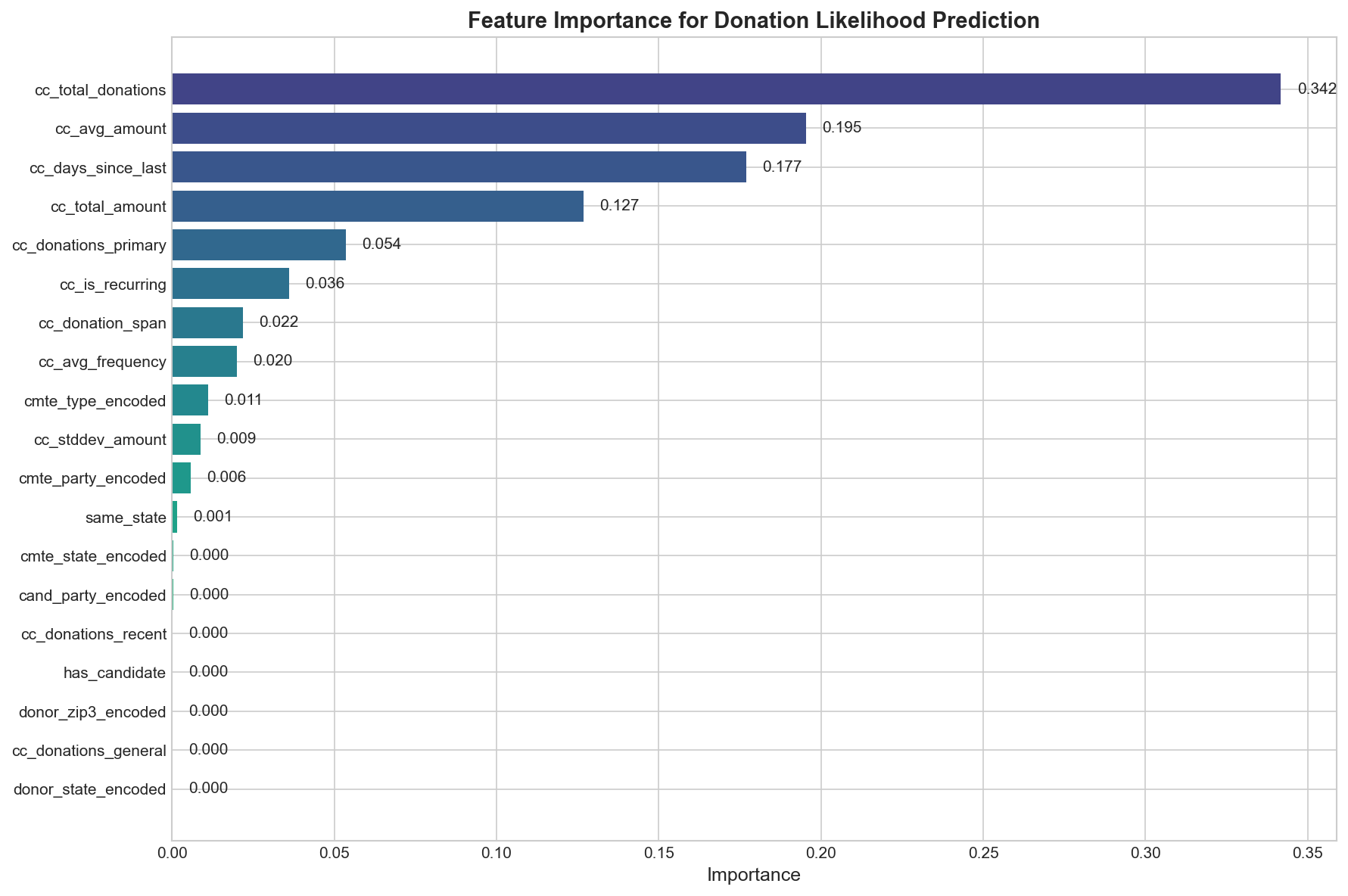
Random Forest feature importance for donation likelihood prediction
Approach & Methodology
The analysis takes a two-pronged approach. First, supervised learning models are trained to predict party affiliation and donation likelihood from contribution features. This helps answer questions like: given a donor's contribution history, can we predict which party they support?
Second, unsupervised clustering using K-Means with KNN indexing identifies natural groupings in the donor population. These clusters reveal patterns that aren't immediately obvious, such as distinct donor archetypes based on contribution behavior.
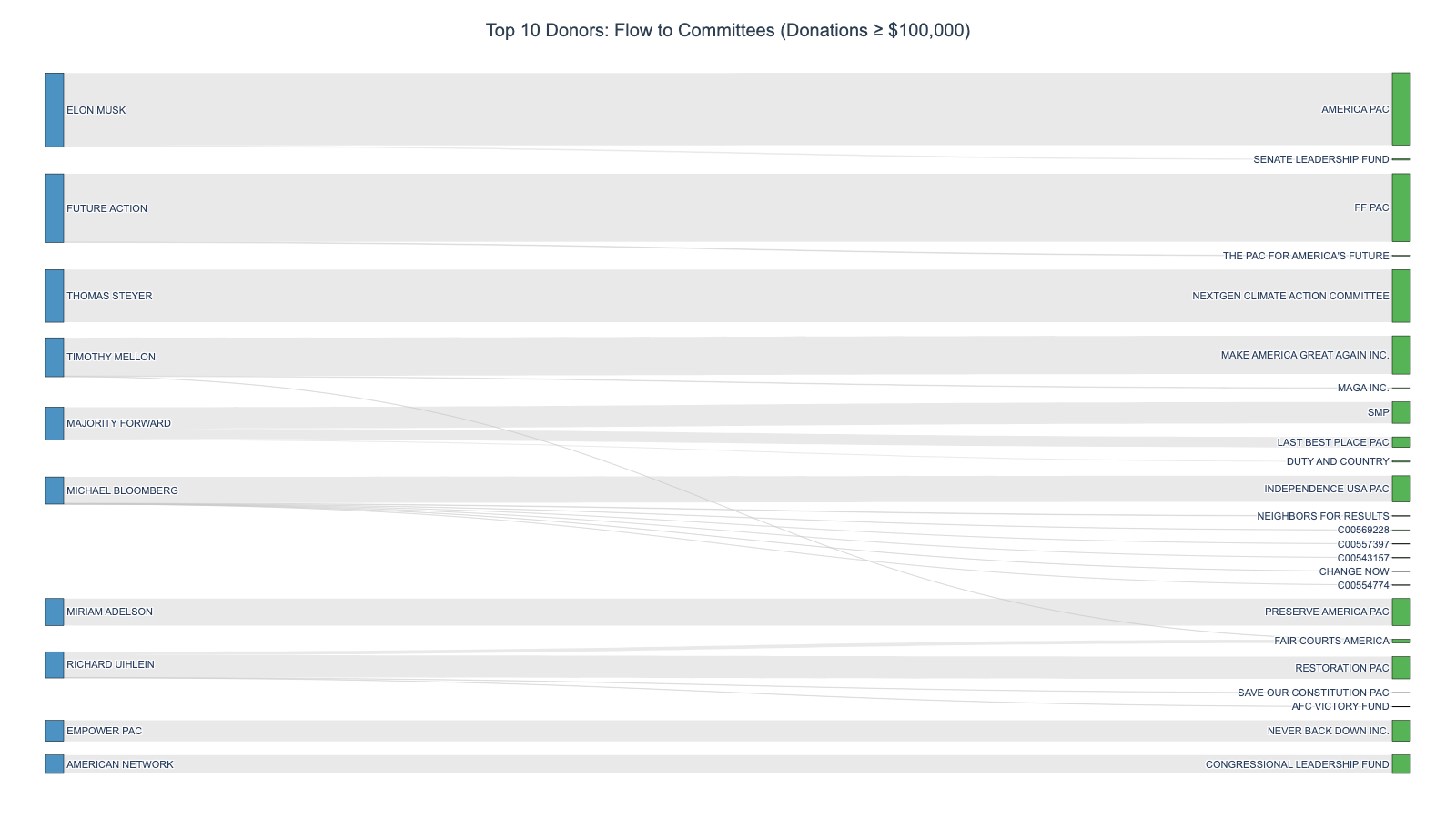
Sankey diagram showing top donor flows to political committees
Insights
Working with real FEC data provided valuable experience in handling messy, large-scale government datasets. The parallel processing pipeline was essential for managing the volume of individual contribution records, and the combination of supervised and unsupervised approaches offered complementary perspectives on political giving patterns.
Back to Home